设计理念
更新时间:
1. 原则层面
-
无 IDL
IDL 是一个很有用的东西,它提供了对接口的描述,约定了接口协议。使得通讯双方通讯时,无需再发送 scheme,有效提高了通讯数据的荷载比。
但同时 IDL 也带来了不少问题,比如强制接口同步修改。如果仅一方接口变动,那对方将无法调用变动方接口。为了解决接口的兼容性,Thrift、Protobuf 等提供了可选参数,以 optional 或类似的关键字标识。但这并不能从根本上解决接口兼容的问题。
首先,开发者必须多学一门语言:IDL 的描述定义语言。这无意中增加了使用门槛和提升了学习曲线。而且,很多初级使用者在不明就里的情况下会大量使用 require 属性,而不是 optional 属性。这就导致为接口兼容而增加的 optional 属性几乎无用武之地。而当开发者再回头修改的时候,则已有大量的代码,和分发出去的应用等待处理。最后往往历史包袱越堆越多,项目中历史遗留问题和历史遗留代码越来越多,而且很难有效清理。
其次,IDL修改后,所有涉及到该IDL的代码依旧得同步修改。否则新加的参数,新加的属性无法和已有代码匹配,造成编译失败。对于时间紧,任务重,人手少,项目忙的团队,无异于是雪上加霜。
再次,很多高级特性无法支持。比如,不定类型的不定长参数。一个等效的例子,C 语言中的 printf 函数。大部分的 IDL 对此类特性,要不很难直接支持;要不就得绕圈子变相支持。
因此,FPNN 决定使用无 IDL 的方式,参考以 JSON 为媒介的数据交换应用,以二进制的方式,来支持以上的特性。
-
多线程 vs 多进程
多进程实现简单,但过多的进程会导致系统负载过大。而且进程间的通讯,效率要远低于线程间的通讯。
FPNN 追求的是性能和效率,因此不会考虑多进程模型。
-
server push
没有 server push,那双工的 TCP 就浪费了一半,也无法有效地实时通知客户方。因此 server push 的支持是一个必须支持的需求。
参考其他能支持 server push 的 RPC 框架,大部分的 server push 实现过重,将会显著地影响服务器和客户端的性能。在海量的用户和海量的数据交换下,server push 实现过重,无异是一种工程灾难。因此 FPNN 决定实现轻巧,但全功能的 server push。
-
提前返回
提前返回本质上是一种异步返回。
在某些需求中,业务可能需要在收到请求后立刻返回。返回之后再继续处理业务。提前返回以同步的外观提供了异步的实现,同时简化了流程操作,无需退出当前的接口函数即可实现异步操作。为了提升开发效率和降低使用难度,提前返回是 FPNN 必须实现的功能需求。
-
禁止使用 Boost 库
Boost 是一个很好的库,而且还是 C++ 的准官方库。C++11/17 标准中的不少内容,就来自于 Boost。但 FPNN 禁用 Boost 的原因其实相对简单:
- Boost 不是操作系统或者编译器自带的库。一旦使用了 Boost,那必须要求目标机也安装和部署 Boost。这无疑增加了额外的工作和负担。而且对于某些小型设备,或者嵌入式来说,体积巨大的 Boost 库无疑是一个工程灾难。
- Boost 库在某些平台下体积巨大。对于某些小型设备,或者嵌入式来说,体积巨大的 Boost 库无疑是一个工程灾难。
- Boost 库太大,不少人并不能完全掌握。一旦使用,将极大的提高开发者和维护者的学习门槛和使用门槛。
-
禁止使用正则表达式和正则匹配
FPNN 追求的是性能和效率,任何开发者不能因自身的懒惰而拖累 FPNN 的性能。
-
尽量少用第三方库
一方面第三方库的的性能未知,另一方面,第三方库在海量压力和极限资源的情况下,稳定性未知。
因此禁止使用未经严格测试的第三方库。
而且过多的第三方库会导致过多的依赖,提高 FPNN 的部署、集成和使用的门槛。
此外,过多的第三方库可能会引入库之间的冲突。无论是第三方库绑定的同一第四方库的版本冲突(感谢某知名图像识别库2011年赐予的宝贵经验),还是名称空间的命名冲突(在C语言实现的第三方库中更加明显)。
2. 实现层面
-
取消 service 层次
某些 RPC 框架,在一个服务进程中,可能会出现一个 service 层次,service 下面的 servant 再提供接口实现。
例如:
scheme://host:port/serive_A/interface_A
scheme://host:port/serive_A/interface_B
scheme://host:port/serive_A/interface_C
scheme://host:port/serive_B/interface_A
scheme://host:port/serive_B/interface_B
scheme://host:port/serive_B/interface_C
这种行为,本质上等价于
scheme://host:port/interface_A_A
scheme://host:port/interface_A_B
scheme://host:port/interface_A_C
scheme://host:port/interface_B_A
scheme://host:port/interface_B_B
scheme://host:port/interface_B_C
将一个方法名分成两部分,在 RPC 层面毫无意义。
因此 fbThrift 等 RPC 框架,也不支持 service 这一层面。
-
同一端口多种协议
FPNN 同一个端口上可以接收
- 未加密的 FPNN 协议
- HTTP 协议 1.0 版本
- 加密的 FPNN 协议
- WebSocket 协议
统一端口支持多种协议的原因很简单:
运维、配置、使用方均简单。
注:开发者不应该因自身的懒惰而将复杂性转嫁给使用方。
-
IPv4 IPv6 双端口监听
目前 IPv4 网络还是主流。但业务上可能需要提供 IPv6 支持。因此很多情况下,IPv4 和 IPv6 运行着相同的业务。
为了能有效平衡 IPv4 和 IPv6 的业务负载,同时减少对系统资源的消耗,如果选择开启 IPv6 端口,则同一 FPNN 服务进程将进行 IPv4 和 IPv6 双端口监听,而不是启动两个独立进程,分别监听 IPv4 和 IPv6。
另外,因为 IP 协议栈位于操作系统内核,所以 FPNN 目前不能在同一个端口上同时监听 IPv4 和 IPv6。
-
不支持STL/HTTPS
- 引入 libopenssl 会导致 FPNN 无法再在同一端口支持多种协议。
- libopenssl 在多线程下会引入全局锁,这对运行时无全局锁的 FPNN 的性能和效率构成重大影响。
- FPNN 自身提供基于 ECC(椭圆曲线加密算法)的秘钥交换(ECDH),和 AES CFB 模式的数据加密。相关细节请参考:FPNN 安全体系
因此,在有更好的解决方案,和更强的需求前,FPNN 暂不支持 STL/HTTPS。仅在 /extends/MultipleURLEngine.h 中,作为客户端使用 libopenssl。
-
不支持 HTTP 1.1 Keep-Alive
FPNN 不建议使用 HTTP 协议。FPNN 对 HTTP 的支持,主要是为了兼顾已有的系统,和小众语言。
因此 FPNN 仅对 HTTP 进行选择性的支持。其中不包含 Keep-Alive。
-
不支持 HTTP 1.1 Pipelining
Pipelining 要求响应按请求的顺序返回。如果某个后位请求的响应速度高于前位请求,也必须等到前位请求的响应发送后,才能发送该后位请求的响应。
对于 FPNN 的流水线而言,Pipelining 的支持不仅复杂化 FPNN 的请求响应处理流程,而且 Pipelining 的流水线模型时效远低于 FPNN 自身的流水线模型。
因此 FPNN 不支持 HTTP 1.1 Pipelining 流水线处理。
-
不支持 HTTP 1.1 和 HTTP 2.0
一方面 FPNN 对 HTTP 的支持主要是出于兼容已有系统和小众语言。高压力高并发模式下强烈不建议采用 HTTP 协议。因此出于性能和效率的考虑,FPNN 也不会支持 HTTP 2.0。
另一方面,不支持 HTTP 1.1 的原因可以参考 “不支持 HTTP 1.1 Keep-Alive” 和 “不支持 HTTP 1.1 Pipelining”。
-
底层链路合并由业务决定,而不是 FPNN 框架
如果同一个进程中,有多个 client 实例链接同一个 endpoint,FPNN 不会自动将链接合并。主要原因是基于以下考虑:
某些长链接业务可能需要用户身份和链接绑定。如果在提供该类服务的代理服务时,势必需要保持各个代理连接的独立性。
因此 FPNN 不会自动将同一进程中链接同一 endpoint 的多个 client 进行链路合并。
如果用户期望链路合并,业务层处理起来也非常简单:
class Holder
{
std::mutex _locker;
std::map<std::string, TCPClientPtr> _linkMap; //-- map<endpoint, FPNN client>
public:
TCPClientPtr getClient(const std::string& endpoint);
... ...
};
即可。
-
必须提供聚合IO操作的 client
作为服务,FPNN 可能执行抓取或者监控任务;作为客户端,FPNN 可能需啊哟同时上传和下载诸多文件。无论是以上哪类情况,进程中都需要有海量的 client 实例存在。如果每个 client 都是IO双线程的形式实现,那伴随着海量的 client 实例,系统中必然会出现海量的线程。而过多的线程会导致系统的性能急速下滑。
FPNN 所以必须提供聚合IO操作的 client,以减少该类需求下,系统中运行的线程数量,以求获得更好的效率和稳定性。
-
RapidJson 和 FPJson 并存
RapidJson 是目前整体性能最好的 Json 操作库。为了性能,FPNN 选择在内部核心操作部分使用 RapidJson。
但 RapidJson 使用过于繁琐复杂,因此对标 Javascript 和 Python 的Json 操作,FPNN 提供了 FPJson。
任何 Json 操作,无论对象层次深度,FPJson 理论上只需要一行代码即可。
3. 框架设计
1. 服务器端
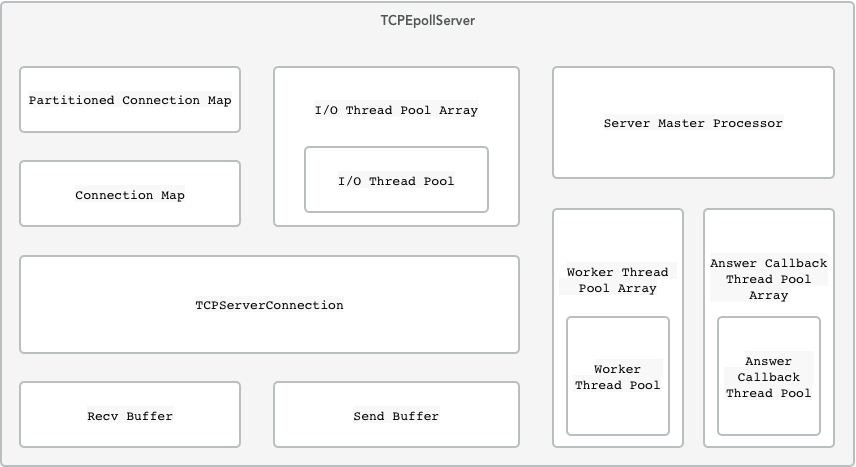
服务器端的核心为 TCPEpollServer,主要结构如下图:
-
PartitionedConnectionMap 保存和控制服务器所有的连接。包含数个 ConnectionMap,为 ConnectionMap 的容器,根据 socket 无锁 hash 后,可获得连接具体保存在哪一个 ConnectionMap 中。
-
ConnectionMap 为最终保存和控制服务器连接的容器。为了避免锁共享,每个 ConnectionMap 保存服务器的一部分连接。
-
TCPServerConnection 为服务器连接类,控制数据的收发和解码。每个连接包含一个 Recv Buffer 和一个 Send Buffer。
-
Recv Buffer 实际控制连接上数据的接收。
-
Send Buffer 实际控制连接上数据的发送。包含有一个本连接的数据发送队列。
-
I/O Thread Pool Array 为 I/O Thread Pool 的无锁 hash 封装。
-
I/O Thread Pool 提供线程,实际执行连接数据的收发和解码工作。
-
Server Master Processor 控制解码之后数据包的分发和请求的处理,以及应答的编码和投递。
-
Worker Thread Pool Array 为 worker Thread Pool 的无锁 hash 封装。
-
Worker Thread Pool 提供线程,实际执行请求的处理,和应答的编码。
-
Answer Callback Thread Pool Array 为 Answer Callback Thread Pool 的无锁 hash 封装。
-
Answer Callback Thread Pool 提供线程,实际执行服务器收到客户端对服务器发出的请求所对应的应答的回调处理。
2. 客户端
客户端分为两类版本:
-
第一类为普通版本,适用于同一进程中只有少量客户端(<10)的情况
该类可用任何兼容FPNN协议的简单客户端逻辑实现。如果实现恰当,性能可高于第二类版本,如果实现不当,性能将会低于第二类版本。
FPNN 暂不提供该类客户端实现。
-
第二类为大量客户端协作版本,适用于进程中可能存在大量客户端(0~100,000)的情况。(包含不连接的客户端。链接中的客户端受系统最大可用端口数的限制(理论上最大65535)。)
该类客户端针对大量并存的客户端,整合并优化了客户端的收发逻辑,使众多客户端在各有不同变现的情况下,共享底层的收发处理逻辑,和相关的系统资源。在收发效率不受明显影响的情况下,极大地减少了系统线程的数量和其他资源的开销。
该类客户端由两部分组成:
- TCPClient
- ClientEngine
TCPClient 为客户端的具体表现,为连接开发者和 ClientEngine 的桥梁。
ClientEngine 为客户端的核心,为全部的 TCPClient 所共享,执行具体的数据收发、编解码、应答回调执行,服务器Push请求处理等操作。
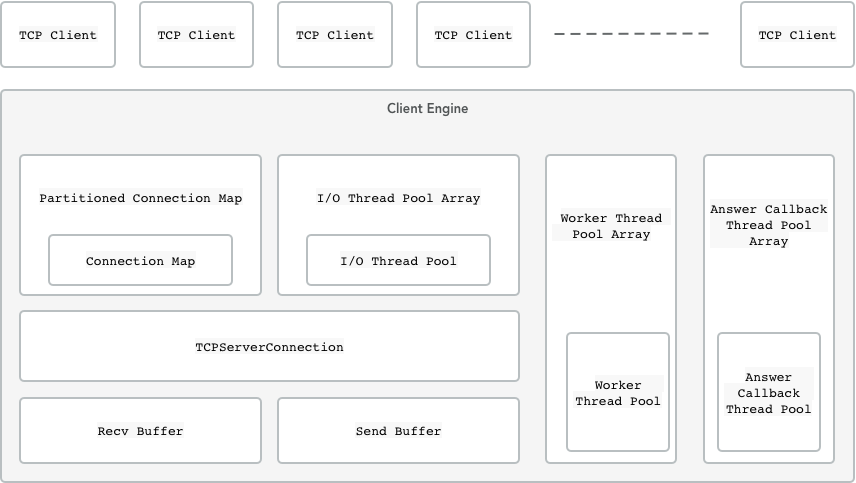
ClientEngine 主要结构、TCPClient 和 ClientEngine 关系如下图:
在 ClientEngine 中:
- PartitionedConnectionMap 统一保存和控制客户端的所有的连接。包含数个 ConnectionMap,为 ConnectionMap 的容器,根据 socket 无锁 hash 后,可获得连接具体保存在哪一个 ConnectionMap 中。
- ConnectionMap 为最终保存和控制客户端连接的容器。为了避免锁共享,每个 ConnectionMap 保存服务器的一部分连接。
- TCPClientConnection 为客户端连接类,控制数据的收发和解码。每个连接包含一个 Recv Buffer 和一个 Send Buffer。
- Recv Buffer 实际控制连接上数据的接收。
- Send Buffer 实际控制连接上数据的发送。包含有一个本连接的数据发送队列。
1. 原则层面
-
无 IDL
IDL 是一个很有用的东西,它提供了对接口的描述,约定了接口协议。使得通讯双方通讯时,无需再发送 scheme,有效提高了通讯数据的荷载比。
但同时 IDL 也带来了不少问题,比如强制接口同步修改。如果仅一方接口变动,那对方将无法调用变动方接口。为了解决接口的兼容性,Thrift、Protobuf 等提供了可选参数,以 optional 或类似的关键字标识。但这并不能从根本上解决接口兼容的问题。
首先,开发者必须多学一门语言:IDL 的描述定义语言。这无意中增加了使用门槛和提升了学习曲线。而且,很多初级使用者在不明就里的情况下会大量使用 require 属性,而不是 optional 属性。这就导致为接口兼容而增加的 optional 属性几乎无用武之地。而当开发者再回头修改的时候,则已有大量的代码,和分发出去的应用等待处理。最后往往历史包袱越堆越多,项目中历史遗留问题和历史遗留代码越来越多,而且很难有效清理。
其次,IDL修改后,所有涉及到该IDL的代码依旧得同步修改。否则新加的参数,新加的属性无法和已有代码匹配,造成编译失败。对于时间紧,任务重,人手少,项目忙的团队,无异于是雪上加霜。
再次,很多高级特性无法支持。比如,不定类型的不定长参数。一个等效的例子,C 语言中的 printf 函数。大部分的 IDL 对此类特性,要不很难直接支持;要不就得绕圈子变相支持。因此,FPNN 决定使用无 IDL 的方式,参考以 JSON 为媒介的数据交换应用,以二进制的方式,来支持以上的特性。
-
多线程 vs 多进程
多进程实现简单,但过多的进程会导致系统负载过大。而且进程间的通讯,效率要远低于线程间的通讯。
FPNN 追求的是性能和效率,因此不会考虑多进程模型。
-
server push
没有 server push,那双工的 TCP 就浪费了一半,也无法有效地实时通知客户方。因此 server push 的支持是一个必须支持的需求。
参考其他能支持 server push 的 RPC 框架,大部分的 server push 实现过重,将会显著地影响服务器和客户端的性能。在海量的用户和海量的数据交换下,server push 实现过重,无异是一种工程灾难。因此 FPNN 决定实现轻巧,但全功能的 server push。
-
提前返回
提前返回本质上是一种异步返回。
在某些需求中,业务可能需要在收到请求后立刻返回。返回之后再继续处理业务。提前返回以同步的外观提供了异步的实现,同时简化了流程操作,无需退出当前的接口函数即可实现异步操作。为了提升开发效率和降低使用难度,提前返回是 FPNN 必须实现的功能需求。
-
禁止使用 Boost 库
Boost 是一个很好的库,而且还是 C++ 的准官方库。C++11/17 标准中的不少内容,就来自于 Boost。但 FPNN 禁用 Boost 的原因其实相对简单:
- Boost 不是操作系统或者编译器自带的库。一旦使用了 Boost,那必须要求目标机也安装和部署 Boost。这无疑增加了额外的工作和负担。而且对于某些小型设备,或者嵌入式来说,体积巨大的 Boost 库无疑是一个工程灾难。
- Boost 库在某些平台下体积巨大。对于某些小型设备,或者嵌入式来说,体积巨大的 Boost 库无疑是一个工程灾难。
- Boost 库太大,不少人并不能完全掌握。一旦使用,将极大的提高开发者和维护者的学习门槛和使用门槛。
-
禁止使用正则表达式和正则匹配
FPNN 追求的是性能和效率,任何开发者不能因自身的懒惰而拖累 FPNN 的性能。
-
尽量少用第三方库
一方面第三方库的的性能未知,另一方面,第三方库在海量压力和极限资源的情况下,稳定性未知。
因此禁止使用未经严格测试的第三方库。
而且过多的第三方库会导致过多的依赖,提高 FPNN 的部署、集成和使用的门槛。
此外,过多的第三方库可能会引入库之间的冲突。无论是第三方库绑定的同一第四方库的版本冲突(感谢某知名图像识别库2011年赐予的宝贵经验),还是名称空间的命名冲突(在C语言实现的第三方库中更加明显)。
2. 实现层面
-
取消 service 层次
某些 RPC 框架,在一个服务进程中,可能会出现一个 service 层次,service 下面的 servant 再提供接口实现。
例如:
scheme://host:port/serive_A/interface_A scheme://host:port/serive_A/interface_B scheme://host:port/serive_A/interface_C scheme://host:port/serive_B/interface_A scheme://host:port/serive_B/interface_B scheme://host:port/serive_B/interface_C这种行为,本质上等价于
scheme://host:port/interface_A_A scheme://host:port/interface_A_B scheme://host:port/interface_A_C scheme://host:port/interface_B_A scheme://host:port/interface_B_B scheme://host:port/interface_B_C将一个方法名分成两部分,在 RPC 层面毫无意义。
因此 fbThrift 等 RPC 框架,也不支持 service 这一层面。
-
同一端口多种协议
FPNN 同一个端口上可以接收
- 未加密的 FPNN 协议
- HTTP 协议 1.0 版本
- 加密的 FPNN 协议
- WebSocket 协议
统一端口支持多种协议的原因很简单:
运维、配置、使用方均简单。
注:开发者不应该因自身的懒惰而将复杂性转嫁给使用方。
-
IPv4 IPv6 双端口监听
目前 IPv4 网络还是主流。但业务上可能需要提供 IPv6 支持。因此很多情况下,IPv4 和 IPv6 运行着相同的业务。
为了能有效平衡 IPv4 和 IPv6 的业务负载,同时减少对系统资源的消耗,如果选择开启 IPv6 端口,则同一 FPNN 服务进程将进行 IPv4 和 IPv6 双端口监听,而不是启动两个独立进程,分别监听 IPv4 和 IPv6。另外,因为 IP 协议栈位于操作系统内核,所以 FPNN 目前不能在同一个端口上同时监听 IPv4 和 IPv6。
-
不支持STL/HTTPS
- 引入 libopenssl 会导致 FPNN 无法再在同一端口支持多种协议。
- libopenssl 在多线程下会引入全局锁,这对运行时无全局锁的 FPNN 的性能和效率构成重大影响。
- FPNN 自身提供基于 ECC(椭圆曲线加密算法)的秘钥交换(ECDH),和 AES CFB 模式的数据加密。相关细节请参考:FPNN 安全体系
因此,在有更好的解决方案,和更强的需求前,FPNN 暂不支持 STL/HTTPS。仅在
/extends/MultipleURLEngine.h 中,作为客户端使用 libopenssl。 -
不支持 HTTP 1.1 Keep-Alive
FPNN 不建议使用 HTTP 协议。FPNN 对 HTTP 的支持,主要是为了兼顾已有的系统,和小众语言。
因此 FPNN 仅对 HTTP 进行选择性的支持。其中不包含 Keep-Alive。 -
不支持 HTTP 1.1 Pipelining
Pipelining 要求响应按请求的顺序返回。如果某个后位请求的响应速度高于前位请求,也必须等到前位请求的响应发送后,才能发送该后位请求的响应。
对于 FPNN 的流水线而言,Pipelining 的支持不仅复杂化 FPNN 的请求响应处理流程,而且 Pipelining 的流水线模型时效远低于 FPNN 自身的流水线模型。
因此 FPNN 不支持 HTTP 1.1 Pipelining 流水线处理。 -
不支持 HTTP 1.1 和 HTTP 2.0
一方面 FPNN 对 HTTP 的支持主要是出于兼容已有系统和小众语言。高压力高并发模式下强烈不建议采用 HTTP 协议。因此出于性能和效率的考虑,FPNN 也不会支持 HTTP 2.0。
另一方面,不支持 HTTP 1.1 的原因可以参考 “不支持 HTTP 1.1 Keep-Alive” 和 “不支持 HTTP 1.1 Pipelining”。
-
底层链路合并由业务决定,而不是 FPNN 框架
如果同一个进程中,有多个 client 实例链接同一个 endpoint,FPNN 不会自动将链接合并。主要原因是基于以下考虑:
某些长链接业务可能需要用户身份和链接绑定。如果在提供该类服务的代理服务时,势必需要保持各个代理连接的独立性。
因此 FPNN 不会自动将同一进程中链接同一 endpoint 的多个 client 进行链路合并。
如果用户期望链路合并,业务层处理起来也非常简单:
class Holder { std::mutex _locker; std::map<std::string, TCPClientPtr> _linkMap; //-- map<endpoint, FPNN client> public: TCPClientPtr getClient(const std::string& endpoint); ... ... };即可。
-
必须提供聚合IO操作的 client
作为服务,FPNN 可能执行抓取或者监控任务;作为客户端,FPNN 可能需啊哟同时上传和下载诸多文件。无论是以上哪类情况,进程中都需要有海量的 client 实例存在。如果每个 client 都是IO双线程的形式实现,那伴随着海量的 client 实例,系统中必然会出现海量的线程。而过多的线程会导致系统的性能急速下滑。
FPNN 所以必须提供聚合IO操作的 client,以减少该类需求下,系统中运行的线程数量,以求获得更好的效率和稳定性。 -
RapidJson 和 FPJson 并存
RapidJson 是目前整体性能最好的 Json 操作库。为了性能,FPNN 选择在内部核心操作部分使用 RapidJson。
但 RapidJson 使用过于繁琐复杂,因此对标 Javascript 和 Python 的Json 操作,FPNN 提供了 FPJson。
任何 Json 操作,无论对象层次深度,FPJson 理论上只需要一行代码即可。
3. 框架设计
1. 服务器端
服务器端的核心为 TCPEpollServer,主要结构如下图:
-
PartitionedConnectionMap 保存和控制服务器所有的连接。包含数个 ConnectionMap,为 ConnectionMap 的容器,根据 socket 无锁 hash 后,可获得连接具体保存在哪一个 ConnectionMap 中。
-
ConnectionMap 为最终保存和控制服务器连接的容器。为了避免锁共享,每个 ConnectionMap 保存服务器的一部分连接。
-
TCPServerConnection 为服务器连接类,控制数据的收发和解码。每个连接包含一个 Recv Buffer 和一个 Send Buffer。
-
Recv Buffer 实际控制连接上数据的接收。
-
Send Buffer 实际控制连接上数据的发送。包含有一个本连接的数据发送队列。
-
I/O Thread Pool Array 为 I/O Thread Pool 的无锁 hash 封装。
-
I/O Thread Pool 提供线程,实际执行连接数据的收发和解码工作。
-
Server Master Processor 控制解码之后数据包的分发和请求的处理,以及应答的编码和投递。
-
Worker Thread Pool Array 为 worker Thread Pool 的无锁 hash 封装。
-
Worker Thread Pool 提供线程,实际执行请求的处理,和应答的编码。
-
Answer Callback Thread Pool Array 为 Answer Callback Thread Pool 的无锁 hash 封装。
-
Answer Callback Thread Pool 提供线程,实际执行服务器收到客户端对服务器发出的请求所对应的应答的回调处理。
2. 客户端
客户端分为两类版本:
-
第一类为普通版本,适用于同一进程中只有少量客户端(<10)的情况
该类可用任何兼容FPNN协议的简单客户端逻辑实现。如果实现恰当,性能可高于第二类版本,如果实现不当,性能将会低于第二类版本。
FPNN 暂不提供该类客户端实现。
-
第二类为大量客户端协作版本,适用于进程中可能存在大量客户端(0~100,000)的情况。(包含不连接的客户端。链接中的客户端受系统最大可用端口数的限制(理论上最大65535)。)
该类客户端针对大量并存的客户端,整合并优化了客户端的收发逻辑,使众多客户端在各有不同变现的情况下,共享底层的收发处理逻辑,和相关的系统资源。在收发效率不受明显影响的情况下,极大地减少了系统线程的数量和其他资源的开销。
该类客户端由两部分组成:
- TCPClient
- ClientEngine
TCPClient 为客户端的具体表现,为连接开发者和 ClientEngine 的桥梁。
ClientEngine 为客户端的核心,为全部的 TCPClient 所共享,执行具体的数据收发、编解码、应答回调执行,服务器Push请求处理等操作。
ClientEngine 主要结构、TCPClient 和 ClientEngine 关系如下图:
在 ClientEngine 中:
- PartitionedConnectionMap 统一保存和控制客户端的所有的连接。包含数个 ConnectionMap,为 ConnectionMap 的容器,根据 socket 无锁 hash 后,可获得连接具体保存在哪一个 ConnectionMap 中。
- ConnectionMap 为最终保存和控制客户端连接的容器。为了避免锁共享,每个 ConnectionMap 保存服务器的一部分连接。
- TCPClientConnection 为客户端连接类,控制数据的收发和解码。每个连接包含一个 Recv Buffer 和一个 Send Buffer。
- Recv Buffer 实际控制连接上数据的接收。
- Send Buffer 实际控制连接上数据的发送。包含有一个本连接的数据发送队列。